Analyzing the First AI Copyright Case from a Technical Perspective | Whoever Owns the Computing Power Monopolizes the Future of Domestic AI Copyrights?
An in-depth technical analysis of the Beijing Internet Court's first AI image copyright case, exploring the application and controversy of the 'originality' standard in AI-generated content.
Introduction
On November 29, 2023, a judgment from the Beijing Internet Court detonated the legal circle.
China finally issued its first judgment document regarding the copyright ownership and infringement determination of “AI-generated image” works.
The author carefully studied the document at the first opportunity.
However, I hold certain dissenting opinions regarding the judge’s determinations.
The judge held that as long as a user undergoes processes such as “designing the presentation of characters, selecting prompts, arranging the order of prompts, setting related parameters, and selecting which image meets expectations,” the generated work can constitute the elements of an “intellectual achievement,” and the user can own the copyright of the output work.
If one is familiar with AI and the technical principles of the Stable Diffusion software,
one can deduce the following fact from this judgment:
In the future, whoever has enough computing power
can monopolize the copyright of domestic AI-generated art works.
Unlike peers who merely analyze the judgment document itself,
the author will attempt to analyze this from a technical perspective,
hoping to bring readers a different angle and experience.
*This article represents only the author’s personal views and is not to be considered as any legal advice or legal opinion.
Thanks to “Zhichanku” (IP Library) for sharing the judgment document.
I. Brief Summary of the Judgment
I believe many readers have seen or heard about the contents of the judgment, but for the convenience of subsequent reading, the author will briefly summarize the case here.
Case Facts:
The plaintiff, Mr. Li, used the Stable Diffusion software (an AI painting software) to generate the image in question and published it on the Xiaohongshu (RED) platform. The defendant, Ms. Liu, a blogger on Baidu’s Baijiahao platform, used the AI image in her blog post without the plaintiff’s permission and cropped out the plaintiff’s watermark from Xiaohongshu, causing relevant users to mistakenly believe the defendant was the author of the work.
Upon discovering this, the plaintiff filed a lawsuit with the Beijing Internet Court, requesting the court to:
-
Order the defendant to issue a public statement apologizing to the plaintiff on the involved Baijiahao account to eliminate the impact caused by her infringement;
-
Order the defendant to compensate the plaintiff for economic losses of 5,000 RMB.
During the trial, the plaintiff also demonstrated step-by-step how to use the Stable Diffusion software to reproduce the process of drawing the AI image in question.
Court Determinations:
1. Whether the image in question constitutes a work, and what type of work it constitutes
Regarding “Intellectual Achievement”:
From the time the plaintiff conceived the image in question to the final selection of the image, throughout this entire process, the plaintiff made a certain amount of intellectual investment, such as designing the presentation of the characters, selecting the prompts, arranging the order of the prompts, setting the relevant parameters, selecting which image met expectations, and so on. The image in question reflects the plaintiff’s intellectual investment, therefore the image possesses the elements of an “intellectual achievement.”
Regarding “Originality”:
The plaintiff designed the characters and their presentation methods through prompts, and set the screen layout and composition through parameters, reflecting the plaintiff’s selection and arrangement. On the other hand, after the plaintiff inputted the prompts and set relevant parameters to obtain the first image, he continued to add prompts, modify parameters, and continuously adjust and correct them, ultimately obtaining the image in question. This adjustment and correction process also reflects the plaintiff’s aesthetic choices and personalized judgment. Therefore, the image in question is not a “mechanical intellectual achievement.” In the absence of contrary evidence, it can be determined that the image in question was independently completed by the plaintiff and reflects the plaintiff’s personalized expression. In summary, the image in question possesses the “originality” element.
Regarding whether it belongs to “Mechanical Intellectual Achievement”:
The plaintiff generated different images by changing individual prompts or individual parameters. It can be seen that by using this model for creation, different people can input new prompts and set new parameters to generate different content. Therefore, the image in question is not a “mechanical intellectual achievement.”
2. Whether the plaintiff enjoys the copyright of the image in question
- The Model:
Because China’s Copyright Law stipulates that an “author” is limited to natural persons, legal persons, or unincorporated organizations, the model used to generate the image cannot become the “author.”
- The AI Software (The creator of Stable Diffusion):
Because it had no intention of creating the image in question, did not pre-set the subsequent creation content, and did not participate in the subsequent creation process, it is merely the producer of the creation tool.
- The Plaintiff:
The plaintiff is the person who directly configured the AI model according to his needs and ultimately selected the image in question. The image was directly produced based on the plaintiff’s intellectual investment and reflects the plaintiff’s personalized expression. Therefore, the plaintiff is the author of the image and enjoys the copyright of the image in question.
3. Whether the alleged act constitutes infringement, and whether the defendant should bear legal liability
The defendant’s act of disseminating the image in question constitutes an infringement of the plaintiff’s “right of information network dissemination” for the work;
The defendant’s act of erasing the plaintiff’s signature when disseminating the image constitutes an infringement of the plaintiff’s “right of authorship.”
Judgment Results:
-
The defendant must publish a statement of apology on her Baijiahao account, maintaining it for at least 24 hours;
-
The defendant shall compensate the plaintiff for a loss of 500 RMB.
II. Why the Copyright Determination Lacks Basis Based on the Principles of SD Software
1. The Operational Principles of Stable Diffusion Software and Its Models
The author has previously discussed the algorithmic principles behind the Stable Diffusion software. Interested readers can refer to:
Briefly, the Diffusion algorithm associates materials in the training set with corresponding annotation information, enabling the algorithm model to learn this correlation and understand the common laws of images in the training set that share the same annotation information. During the training process, by simulating various possibilities of distributing pixels (i.e., “paths”), it generates images to satisfy these common laws. In the generation phase, we match the inputted requirements (i.e., “prompts”) with the annotation information from training, search for the generation path that best fits the image represented by this annotation information, and finally generate an image that matches the content of the prompts.
The parameter “Seed” in the Stable Diffusion software represents a specific “path.”
2. Using the Same “Path” Inevitably Leads to a Unique Result
In the judgment, we learn that the plaintiff demonstrated in court how he reproduced the image in question by re-inputting the relevant positive and negative prompts, iteration steps, LoRA model weights, and other parameters, while fixing the “seed”.
This actually means that the image in question is essentially the result of “mechanical generation” based on fixed parameters.
“Reproducibility” is also the biggest feature distinguishing Stable Diffusion from other AI generation software (such as Midjourney, DALL·E, etc.).
On the well-known AI model sharing website Civitai, there are massive amounts of AI images shared by users. These images contain the specific models used (Resources) as well as the parameters used during generation (Generation Data), and the website even provides a “one-click copy” function for parameters.
 (Model Sharing Page)
(Model Sharing Page)
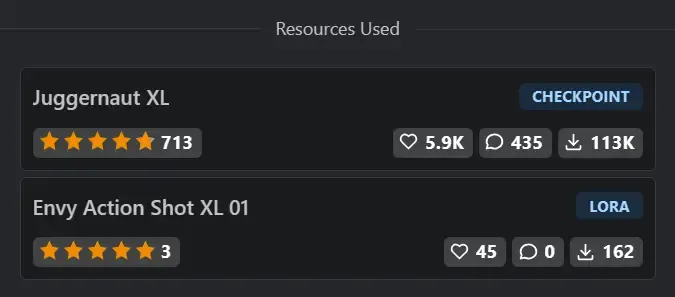 (The models used for the image)
(The models used for the image)
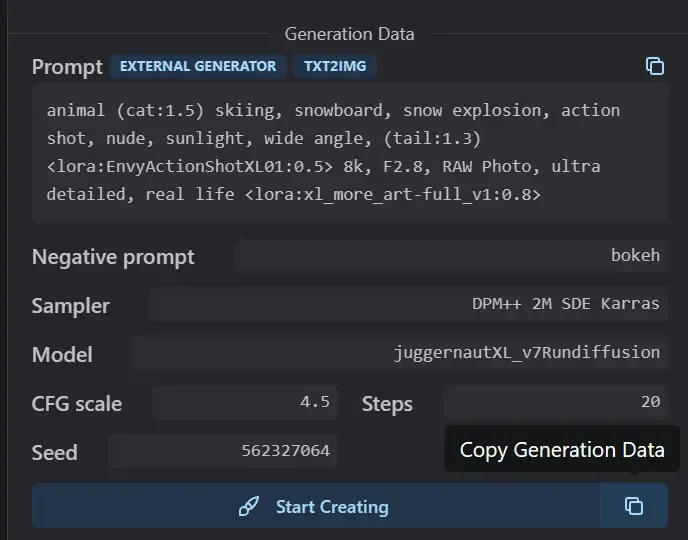 (The generation parameters used for the image)
(The generation parameters used for the image)
By clicking the copy button, the generation parameter information obtained is as follows:
animal (cat:1.5) skiing, snowboard, snow explosion, action shot, nude, sunlight, wide angle, (tail:1.3) lora:EnvyActionShotXL01:0.5 8k, F2.8, RAW Photo, ultra detailed, real life lora:xl_more_art-full_v1:0.8
Negative prompt: bokeh
Steps: 20, VAE: sdxl_vae.safetensors, Size: 832x1216, Seed: 562327064, Model: juggernautXL_v7Rundiffusion, Version: v1.6.0-2-g4afaaf8a, Sampler: DPM++ 2M SDE Karras, VAE hash: b3165c12ca, CFG scale: 4.5, Model hash: 0724518c6b, “EnvyActionShotXL01: 46f3acce826a, xl_more_art-full_v1: fe3b4816be83”
Other users only need to download and use the same models, and import the copied generation parameters into their software interface with one click to reproduce this image on their own devices.
Although the final result may not be 100% perfectly replicated due to the influence of computer hardware, plug-in versions used by the software, model versions, etc., the generated results are sufficient to constitute “substantial similarity.” Below are some images tested by netizens:
 (Source: https://www.tonyisstark.com/869.html)
(Source: https://www.tonyisstark.com/869.html)
 (Source: https://www.bilibili.com/read/cv23375108/)
(Source: https://www.bilibili.com/read/cv23375108/)
Based on the parameters recorded in the judgment document, and without knowing the software version, plugins, hardware devices, or the unmentioned parameters, the author was also able to reproduce the following results on my computer. Apart from the body, the face, background, and lower body clothing show obvious similarity, and the overall composition is also very similar:
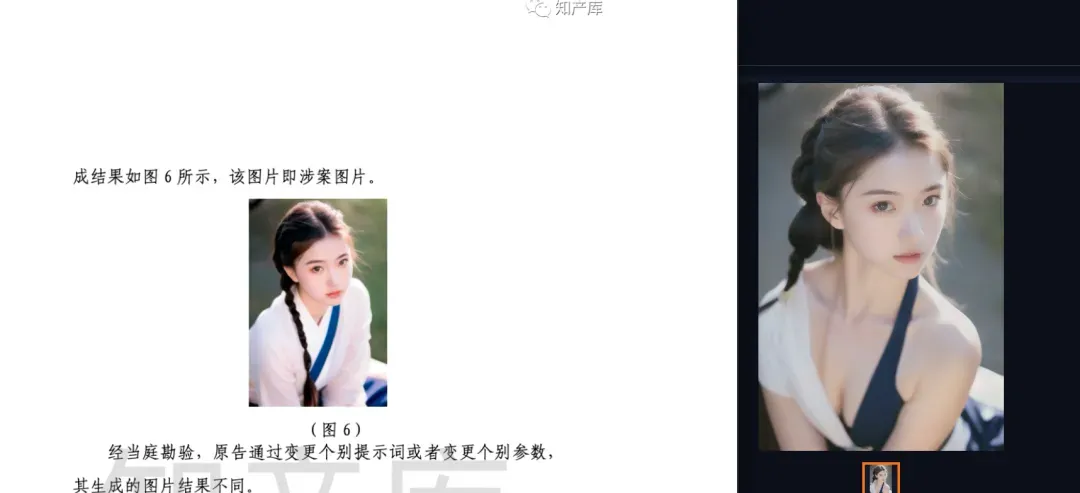
And when the factors affecting the results are minimized, it will achieve a 100% identical generation result, just like the plaintiff’s reproduction process.
To further demonstrate this, the author records a test result here:
- After inputting all basic generation parameters into Stable Diffusion, keep the random seed at -1 (i.e., randomly generate a seed, which is the normal workflow for generating AI images; in actual use, one almost never fixes the seed before adjusting parameters), and click generate.
- Obtain the first generation result and its seed parameter:
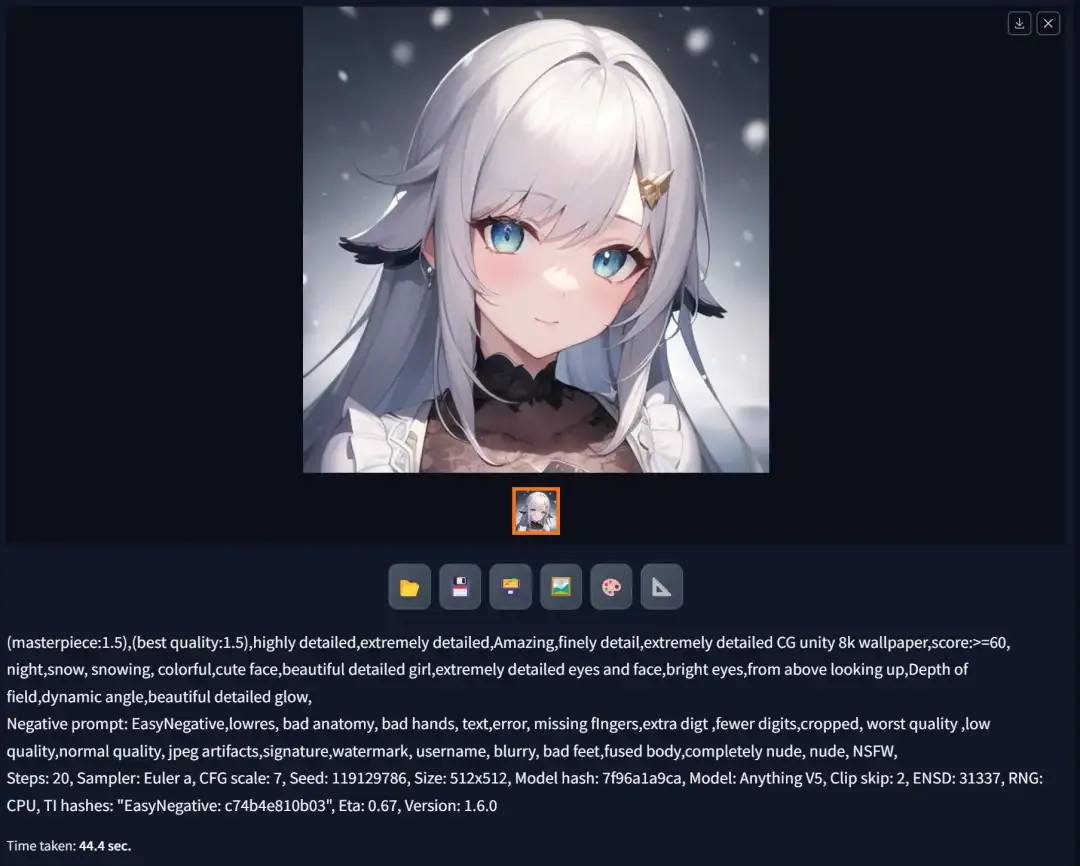
- Restart the software, input the exact same parameters again, modify the seed parameter to match the result from the second step, and click generate again:
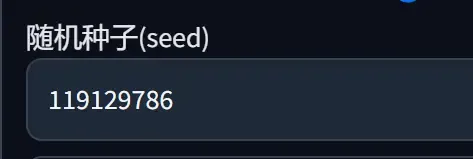
- Obtain the exact same image:
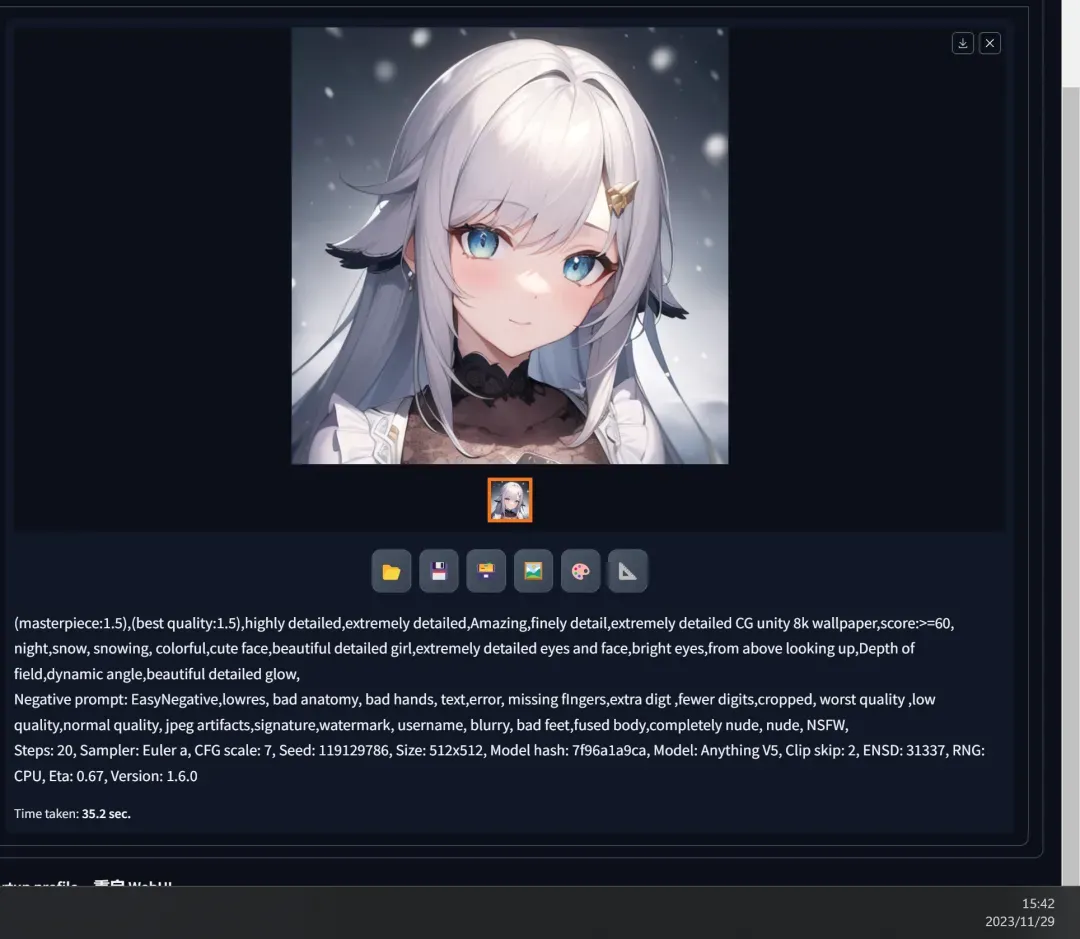
It is evident that, under the condition of using the same models and generation parameters, using the same “seed parameter” can generate an image that achieves “substantial similarity” or even an “identical” result.
3. AI-Generated Images are merely “Mechanical Intellectual Achievements” calculated through a certain method
Whether it is the reproduction process demonstrated by the plaintiff in the case or the test results above, all point to a single fact:
The so-called “AI painting” is merely a process of calculating based on the formulas within the algorithm, combined with input parameters, among the massive magnitude of possibilities generated during the model training, thereby pointing to a specific result and generating the corresponding image.
The various adjustments the plaintiff made during the reproduction process essentially have absolutely nothing to do with the final result. The process of adjusting parameters merely points to different generation results of the model. As long as the final input parameters match the parameters of the generated image, no matter how many magnitudes of adjustments were made previously, the final result will not change. It is as fixed and accurate as 1+1=2 in a universal environment.
Just as the judgment elaborated on “mechanical intellectual achievement”:

No matter who the generator is, as long as they choose the same model, input parameters in a certain sequence on the same equipment, the AI image result generated after clicking the mouse will definitely be the same, and it has absolutely no relationship with the person, time, or place the mouse was clicked.
“AI-generated images,” at least at the current stage, are merely “mechanical intellectual achievements.”
4. We are just “Picking the Monkey’s Selfie”
In this case, the judge believed that the plaintiff’s process of adjusting and modifying parameters reflected the plaintiff’s aesthetic choices and personalized judgment:

However, through the above discussion, we can now judge that the plaintiff (and even us who use AI drawing) is merely selecting an image that conforms to human aesthetics from a pile of “mechanical intellectual achievements.”
The judge used the example of a “camera” in the judgment. Here, the author also wants to quote another “camera” example:
In 2011, British photographer David Slater was taking photos in the wild in Indonesia. During the shoot, he fixed his camera on a tripod and deliberately left the remote shutter release so that macaques could approach the camera. A female macaque pressed the remote shutter release and took a large number of photos. Most of these photos were blurry and unusable, but Slater selected the two most interesting ones and subsequently published them on his website:

Wikipedia placed these two photos on its website and declared they were “taken by a monkey,” which made Slater believe Wikipedia infringed his copyright. Slater sued Wikipedia’s parent company in court. Later, in December 2014, the US Copyright Office determined that it was indeed “taken by a monkey” and stated that works not created by humans are not subject to US copyright; in 2016, a US federal judge ruled that monkeys cannot hold the copyright to these images themselves; in 2018, the Ninth Circuit Court of Appeals upheld the original verdict.
If we draw an analogy to this case, the plaintiff’s actions are no different from Slater’s. Their essence is just selecting from a pile of works not created by humans. The plaintiff’s process of adjusting parameters is just “changing hand gestures in a black box full of various images to pull out a specific one,” and this image inherently does not include any part “created” by himself.
Just as the popular colloquial term for “AI drawing” is: “Gacha” (drawing a lottery). We do not consider the process of a lottery draw (even if we set the parameters of the prize’s type, color, size, shape, probability, etc. ourselves) as a “creation process,” nor do we consider the prize drawn to be a “work” over which we hold copyright. Similarly, we should not determine that the “lottery drawer” holds the copyright of the “work” “drawn” during “AI painting.”
5. Even Prompts Lack the Elements of “Creation”
Readers familiar with Stable Diffusion might know that there are many prompt plugins available online, and simultaneously, numerous netizens share various practical prompt templates on sharing websites, forums, and blogs.
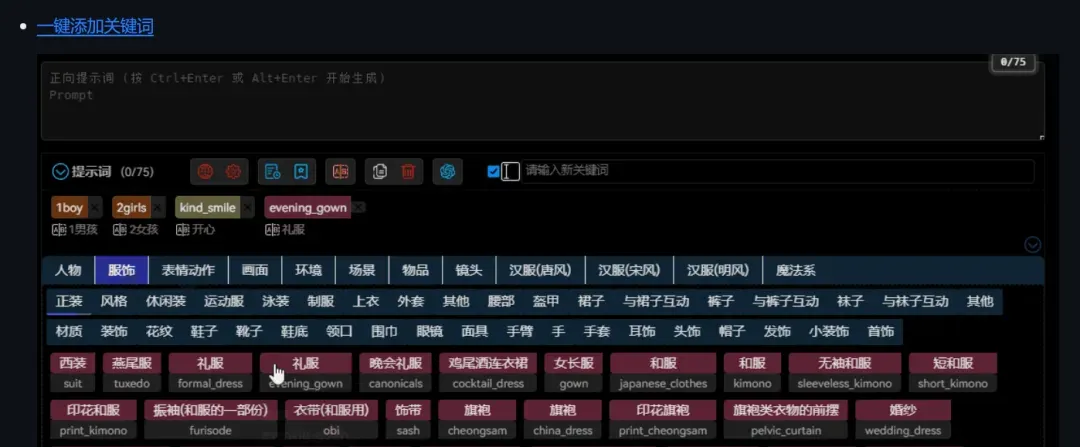 (For example, a plugin that can add prompts with one click)
(For example, a plugin that can add prompts with one click)
When using LoRA models, trigger words are often required; otherwise, the final generation result cannot apply the LoRA model’s effect:
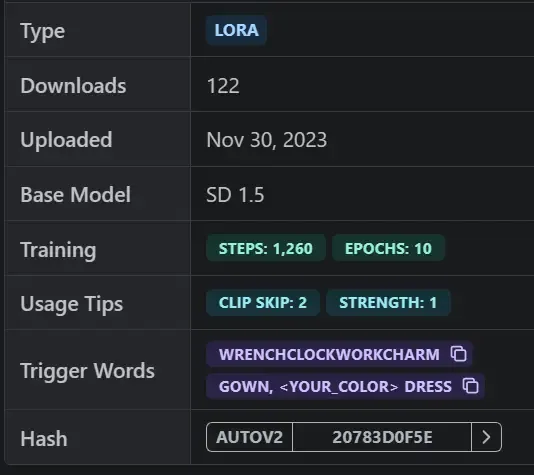 (Trigger Words, which must be inputted into the positive prompts)
(Trigger Words, which must be inputted into the positive prompts)
The reason for such numerous restrictions is that the scope of prompts that can be inputted and affect the generation result is positively correlated with the “tags” in the model’s training set.
No one can input prompts beyond the scope of the “tags,” nor can they “create” content beyond the tags already existing in the model. Otherwise, the drawing program will be unable to understand the meaning of the prompt and cannot generate elements related to this prompt in the output result.
The plaintiff also mentioned during the trial that the prompts used in his “creation” process were mostly copied directly from others’ templates:

And the negative prompts he edited himself did not exceed the common scope; they were merely selected from within the existing range, not the result of his “independent creation.”
6. Looking at the Entire “Creation” Process, the Plaintiff Possessed No “Creative” Act and Should Not Obtain Copyright
Through the above analysis, we can now reach a conclusion:
Whether the plaintiff was inputting parameters, adjusting parameters, or selecting generation results, he was merely operating within the “possibilities” the model could provide. The essence of AI-generated images is only related to the equipment, model, and software; it has no correlation with the user. Anyone, using the same equipment, model, and software, can transcend time and space to obtain exactly the same result. Therefore, the AI-generated images in question fully conform to the definition of “mechanical intellectual achievement.”
When users directly use AI generation results, they are merely undergoing a selection process based on human aesthetics, which has no correlation with the creation of the image and lacks the elements of “creation.” Their act of inputting parameters only limits the scope of “possibilities” and has no connection with the production of the outcome, failing to meet the requirement of influencing the generated result “through the investment of intellectual elements.”
Thus, whether analyzing from the essence of the images in question or based on the plaintiff’s generation process, the plaintiff should not enjoy the copyright of the work in question (more appropriately called the “image in question”).
III. Other Detail Issues in the Judgment
In addition, there are other detailed issues in the judgment:
1. The Plaintiff’s Reproduction Process Lacks the Evidentiary Power to Prove His Creative Act
The judgment mentioned that precisely because the plaintiff’s behavior of “adjusting parameters” shown in the reproduction video demonstrated a process of “aesthetic choice and personalized judgment,” it concluded that the image in question has “originality.”
Unlike traditional digital art source files which contain information like layers and operation logs, AI drawing (in the case of Stable Diffusion) only has the generated image and the generation parameter information carried within the image; it does not contain any record of the “process.”
As mentioned above, as long as the final parameters are consistent, no matter what complex debugging process is shown in the “reproduction video,” an identical image can be generated.
The author will illustrate this again through the previous example:
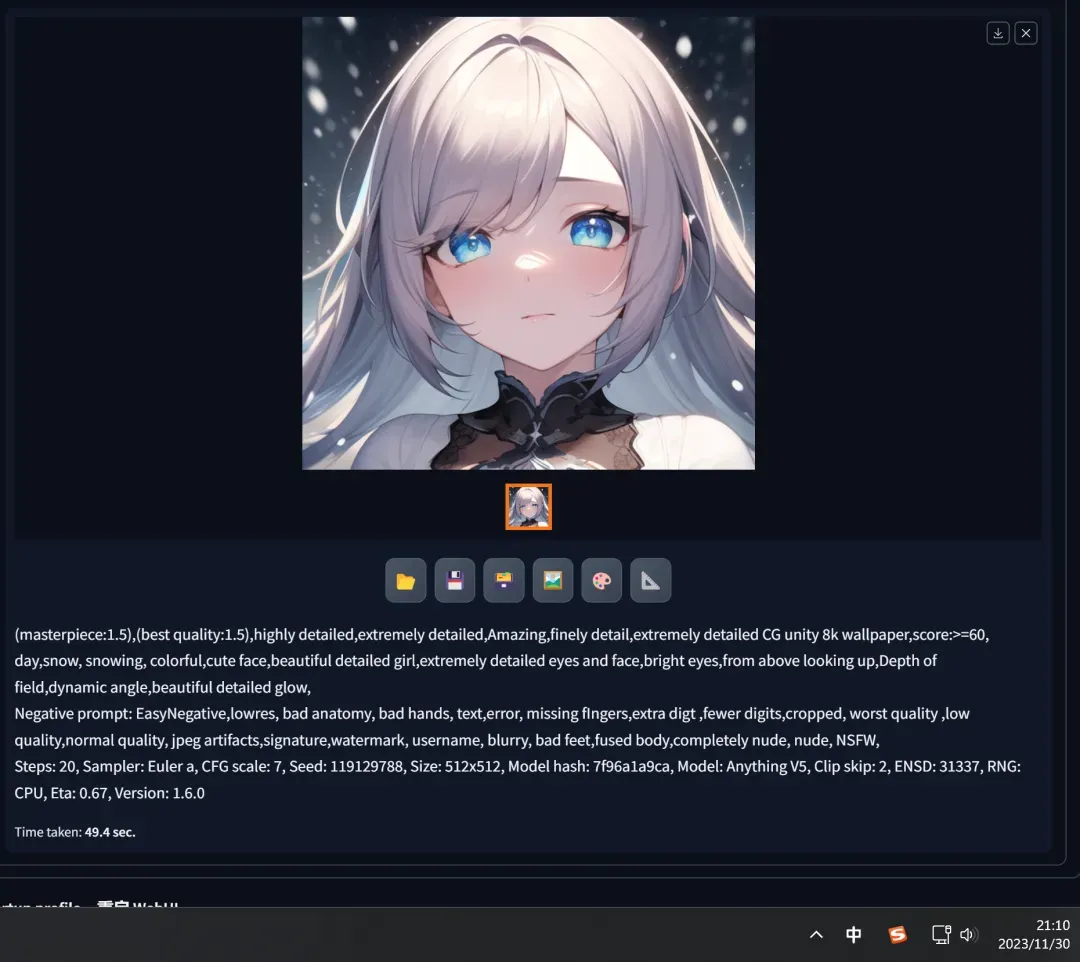
- In Stable Diffusion, without changing the seed, adjust one of the keywords from “night” to “day,” click the generate button, and get a completely different image:
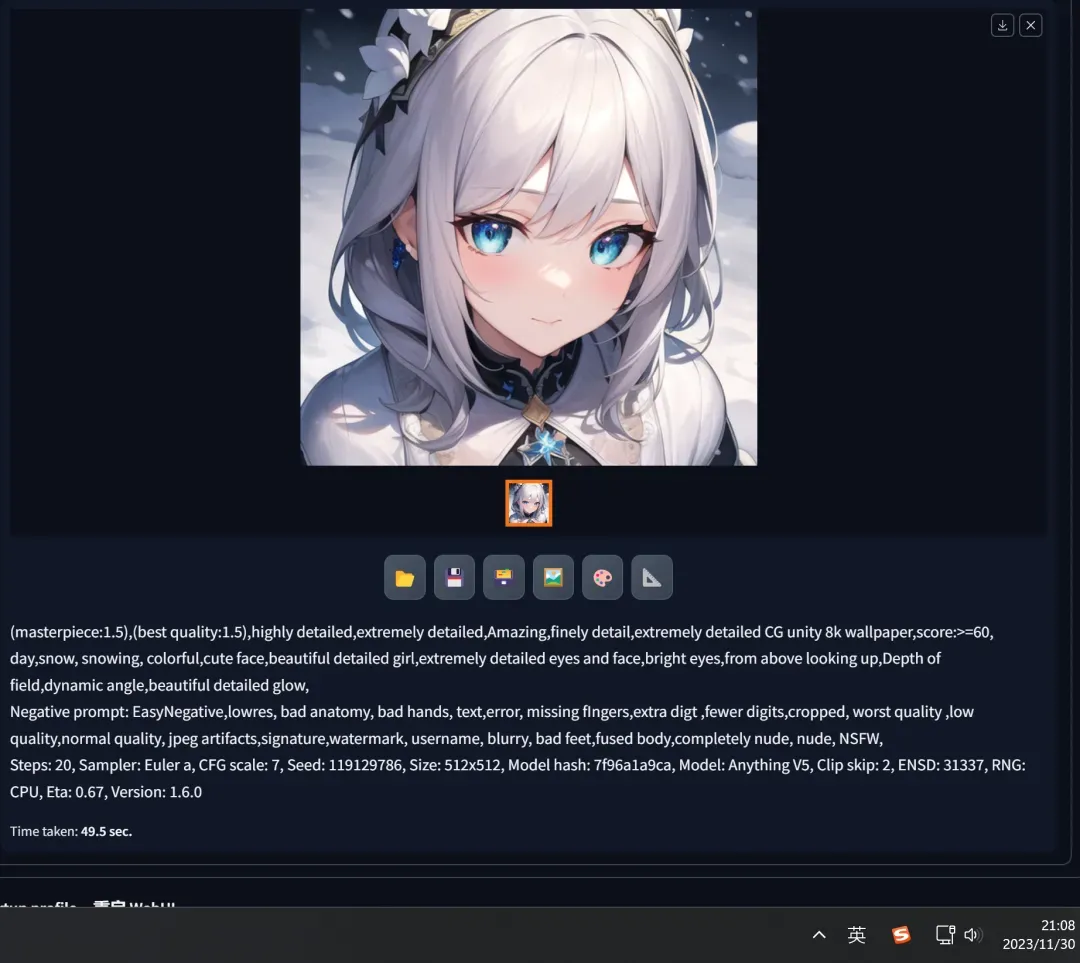
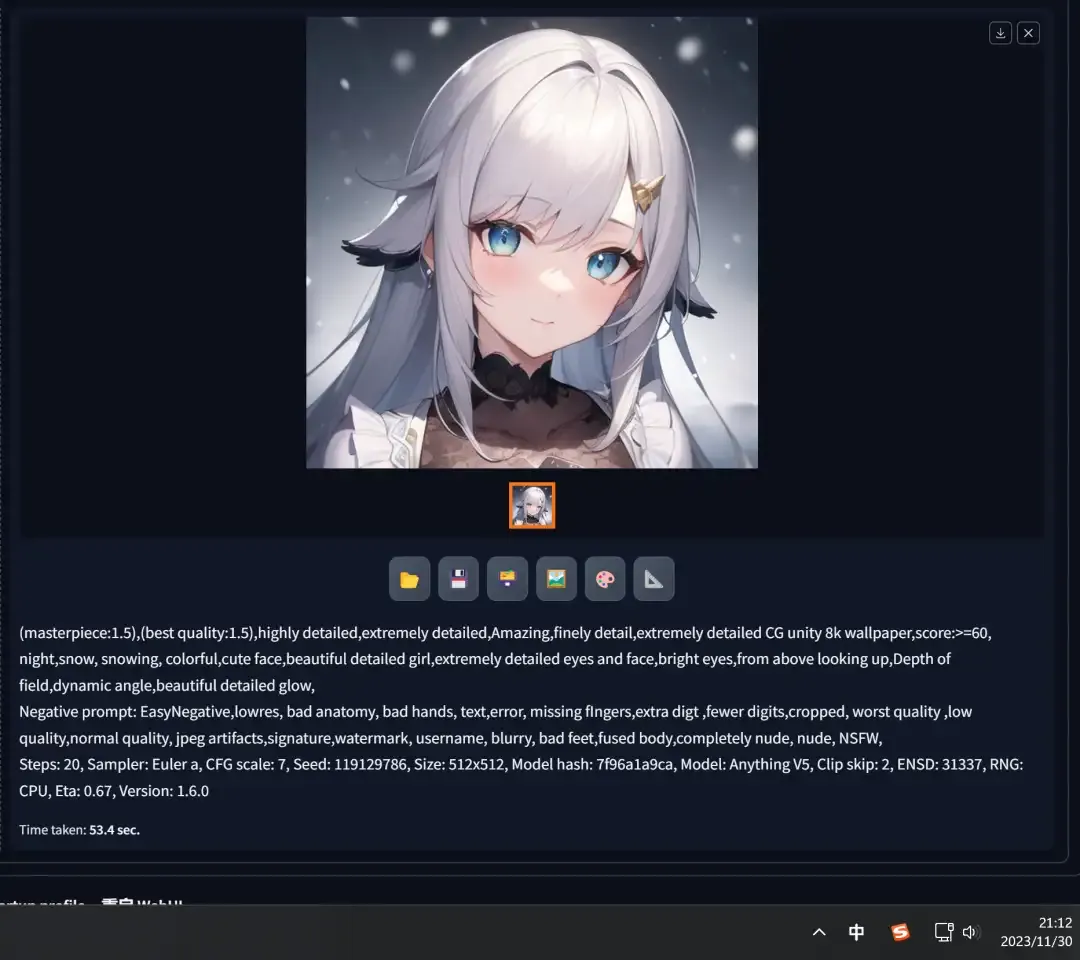
- Then keep the current prompts unchanged, modify the “seed” to “119129788” and click the generate button, obtaining another different image:
- Finally, change the prompts and “seed” back to their original versions, press generate again, and as you can see, the original image is completely “reproduced”:
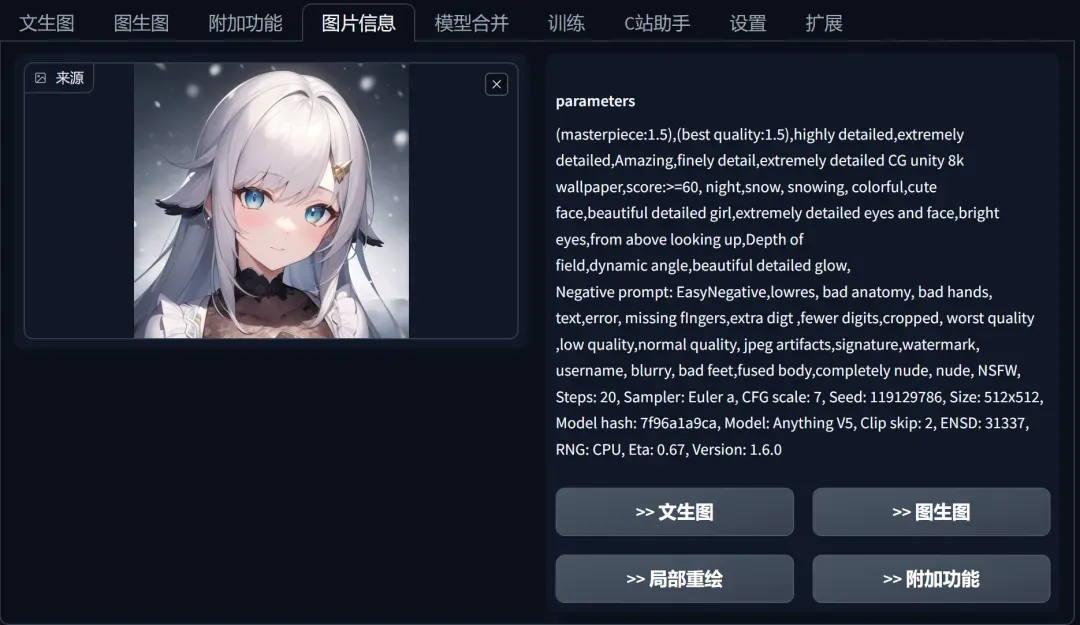
In fact, anyone can read the generation information of any previously batch-generated image through Stable Diffusion’s “PNG Info” function, send it to the “Text to Image” function, readjust the parameters, and get different generation results. Of course, it can also be used to reproduce identical images.
Although there is no evidence to prove that the plaintiff engaged in “reverse-engineering the creation process,” strictly in terms of “evidentiary power,” the plaintiff’s reproduction video is insufficient to prove his “creation process.”
2. The Plaintiff’s “Creation Process” Notably Contradicts Common Sense
“AI drawing” is a “gacha” (lottery-drawing) process. No one knows what the result of the “draw” will be. Therefore, mainstream (and the vast majority of) Stable Diffusion tutorials and ordinary user generation operations involve using a random seed to batch-generate a large number of different images, and then selecting an image “conforming to human aesthetics” from them (based on a certain “seed”). Because we cannot know in advance which “seed” will fit our aesthetics, randomly generating a variety of different “seeds” in batches and then selecting from them is the optimal solution.
However, the plaintiff’s “reproduction process” went in the exact opposite direction: first fixing the “seed,” then adjusting the LoRA model, and then generating the image by adjusting the “seed” and prompts again.
Fixing the “seed” first during generation means only one image can be generated at a time. This holds no obvious advantage in terms of either practicality or efficiency.
Especially when modern consumer graphics cards can generate an image in seconds, selecting from a massive batch of generated images is far more effective than “randomly inputting a seed.”
However, the author does not rule out that someone might actually generate images in this manner, or the plaintiff might have adopted this method merely for the convenience of demonstration.
The author is only stating this based on “general rationality” and does not imply that the plaintiff definitely “reverse-engineered the creation process.”
IV. Potential Impacts of this Case
Assuming this case becomes a “precedent” for future related judgments, it may bring the following impacts on the domestic copyright environment:
1. It May Change the “Natural Ownership” Trait of Copyright
According to Article 2 of the Copyright Law, a work enjoys copyright regardless of whether it is published, which means “natural ownership.”
Article 2: Works of Chinese citizens, legal persons or unincorporated organizations, whether published or not, shall enjoy copyright in accordance with this Law. — Copyright Law of the People’s Republic of China
However, based on the principles of AI drawing, due to the uniqueness of the “seed” result, anyone could potentially own the “copyright” of the same or a similar image. The only factor affecting the acquisition of this image’s copyright is simply who clicked the mouse earlier and “luckily” randomized onto this “seed.”
This leads to a bizarre phenomenon:
The copyright owner of a work could be anyone, until a certain mouse click collapses it into a specific result.
The copyright owners of a work could also be more than one person, as long as they are all “lucky” enough to randomize the same result.
Especially when the model is smaller and the possibilities are fewer, the likelihood of generating similar images is higher. When people generate similar images, it easily leads to disputes over “who is the true copyright owner of this image” and “who infringed upon whose rights.”
Based on timestamp priority?
But the nature of electronic data is that it is “freely modifiable.” Anyone can change the generation time of an image by adjusting the device’s clock, for example, rewinding it two months:
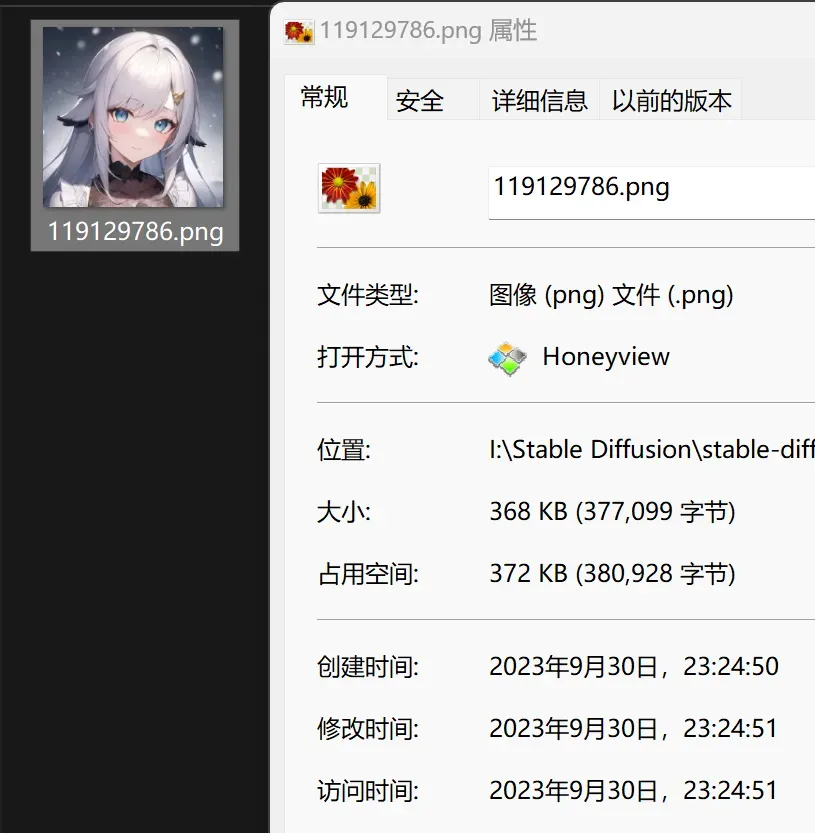
With current technology, it is incredibly difficult for most people to verify the true generation time of an AI-drawn image, making it hard to determine priority rights.
Based on who published or deposited evidence first?
That would severely undermine the “natural ownership” right of copyright, turning it into “first to claim owns it.” Anyone could lose the copyright to a work simply because they “published it late,” or just saved it on their hard drive or in drafts, or thought about “using it next time.”
This causes “copyright” to no longer align with “creation equals ownership.” Instead, potential rights holders will have to fight for copyright via massive reliability proofs, otherwise facing the risk of losing their copyright for no reason.
2. It May Shift Copyright from Protecting “Creation” to Protecting “Results”
The “result” of traditional works is the embodiment of the creative process, and the essence of protecting a work is protecting the complete “creative act.” This is also the core idea of copyright: Protecting expression.
When AI works are generated using the same creation process, keeping other parameters constant, a completely different result can often be obtained just by slightly adjusting the “seed” parameter.
In this case, the judge believed that the plaintiff’s “creation process” possessed “original intellectual investment” and thus deserved protection.
But the question is, what kind of “creation process” should we be protecting?
Is it the adjustment process experienced while generating the AI image?
Is it the final parameters used to generate the AI image (normally, the creative process doesn’t involve thinking about the “seed”)?
Or is it the final AI image file generated when the creator clicked the mouse (which includes the final parameters containing the “seed”)?
If one believes we should protect the “thinking process” and therefore the final generation parameters, this means one person could monopolize the copyright of all possible images (all “seeds”) under those parameters. Based on fairness, this is clearly unfeasible.
If one believes only the final generated result should be protected, this means anyone can easily take another person’s cognitive output—the “original intellectual investment” determined by this case—and by simply inputting a random new “seed,” effortlessly obtain a new image result that possesses slight differences and is hard to classify as infringement under traditional legal definitions.
In traditional art, this might be equivalent to merely “adding a brushstroke” of effort, without needing to add any meaningful “intellectual investment,” yet one could shockingly acquire full copyright of a new work.
From a judicial standpoint, however, “protecting the result” is the easiest way to determine infringement. When the generation information is scrubbed from a work, the only possibility left to judge infringement is “visual similarity.” But in AI drawing, changing the visual similarity of the final product is precisely the part that requires the least “intellectual investment.”
Protecting “parameters” easily leads to over-protection;
Protecting the “final product” essentially fails to protect the “thinking process” and merely protects a “mechanically generated result” beyond human intervention.
3. The Copyright Determination Method is Hard to Apply Across Different AI Software, Easily Causing Discrimination
Since Stable Diffusion requires a certain technical foundation to set up, more people might choose domestic and foreign AI drawing platforms like Midjourney, DALL·E, and ERNIE Bot (Wenxin Yiyan).
The characteristic of these platforms is that users don’t need to worry about specific generation parameters and models; they just need to input prompts to output an image result.
Their output results are completely random. Even identical prompts cannot reproduce the same image; nor is it possible to adjust details based on a certain image—each time is a regeneration based on prompts.
When using these platforms, the users’ “original intellectual investment” will be significantly lower than that of Stable Diffusion users because they cannot adjust various parameters.
If the same judgment standard as this case is applied, can these users also obtain copyright for their generated results?
Even if the users only inputted a short line of prompts?
If it is believed that copyright should be protected, should it protect the prompt, or that completely random, unreproducible generated result?
If it is believed that a single sentence prompt alone cannot constitute “intellectual investment,” then does a person using AI drawing with higher technical abilities or more complex software possess more rights than others?
In traditional creative software, whether using the system’s built-in drawing app or a downloaded premium drawing software, creators enjoy the same copyright over their original images.
But in the realm of AI drawing software, determining that only the act of inputting prompts AND adjusting parameters constitutes creation artificially erects barriers and discrimination, which is manifestly unfair.
4. It May Lead to Computing Power Monopolizing Copyrights
If the current principles of copyright are not changed, solely based on the determinations in this case, we can deduce a terrifying conclusion:
In the future, whoever possesses more hardware computing power can generate more images faster and obtain more copyrights.
If it is recognized that a user owns the copyright to AI-generated images, and since “creation process” and “creation time” cannot be falsified, a creator with more computing power could continuously and randomly generate images for a certain model based on various parameters, exhausting the possibilities of generation results to achieve a monopoly on the copyrights of the images that model can generate.
Furthermore, because of the uniqueness of the “seed” result, after discarding most results that do not conform to human aesthetics, the actually usable “seeds” might be limited. Ordinary people might lose the copyright to a usable image generated by that model simply because their hardware is inferior and they generated it later. This could even lead to them committing infringement due to using a substantially similar image—readers familiar with current Stable Diffusion software should clearly understand how high the similarity and frequency of identical outputs can be from small models, especially small LoRA models.
The author believes this presents a future possibility where physical assets monopolize intellectual property.
In the judgment, the judge reasoned that AI drawing software is a new technological tool, and by correctly applying the copyright system, more ordinary people can be encouraged to participate in the creative process.
Although the starting point is good, this clearly only considers the “human” participation part, ignoring the “machine” participation part.
The production efficiency of traditional works is entirely tied to human creative ability and efficiency; everyone’s opportunity to produce works and gain copyrights is equal.
However, the production efficiency of AI-drawn works has a tremendous correlation with machine performance, with disparities reaching dozens or even hundreds of times.
To give a personal example, currently, a flagship consumer graphics card like the Nvidia RTX 4090 can generate an image in 1 second using Stable Diffusion, whereas the author’s own graphics card often takes nearly 50 seconds.
If it is deemed that AI software users hold copyright over the generated images, this 50-fold difference is a 50-fold gap in copyright acquisition efficiency. When both use the same model to generate images, the person with the 4090 might “draw” a usable image much earlier, leaving the author with a much higher probability of infringing.
This unfair reality should not become the future of China’s copyright.
V. Personal Views: Copyright Ownership of Training Sets, Models, and Generated Works in AI Drawing
Regarding the new intellectual property controversies brought by AI, the author would like to share personal views on the copyright ownership of the three core elements of AI drawing, hoping to throw out a brick to attract jade (invite valuable discussion):
1. Training Sets
Training sets can be simply understood as various work images collected to train the model. The author believes there are two categories here: Fully Original Training Sets and Training Sets Containing Third-Party Works.
A fully original training set means all works within it are legally owned by the model creator themselves. The copyright of this training set belongs entirely to the model creator and won’t infringe on any third party’s rights. This likely needs no further debate.
A training set containing third-party works, as the name suggests, includes third-party works partially or entirely. The author believes that in such sets, the copyright of the third-party works remains with the third parties, while the copyright of the training set itself (as a compilation work) belongs to the collector. The act of collecting and using them to train a large model does not infringe upon third-party rights, unless works explicitly marked as not allowed for AI training are used.
The author has expressed similar views in previous articles (see the linked article earlier in this text). The AI model training process, at least for the Diffusion algorithm, is merely learning commonalities. The commonalities of human works cannot depart from shared human culture, thought, and aesthetics. Even if a work has innovative parts, in an absolute large model, this innovation will appear insignificant (the infringement issue of LoRA models was analyzed in the previous article and won’t be repeated here). The final generated large model will inevitably not infringe upon the copyrights of the authors in the training set.
However, the author also respects every copyright owner’s right to protect their works. Declaring “not allowed for AI training” is the right of the copyright owner, and training set collectors have an obligation to respect this right.
2. Models
AI models here specifically refer to models that have been trained using training sets and specific algorithms, directly usable for reasoning and generating AI drawing outputs.
The author believes the copyright owner of such a model is its creator. However, unless a fully original training set was used, the model copyright owner does not enjoy the copyright of the works generated by the model.
When a fully original training set is used, it means the model’s generation results carry the characteristics of the works over which the model copyright owner holds copyright. Although this characteristic is also based on social commonalities, it contains more of the copyright owner’s “thinking results” and is a summary and induction of past “intellectual achievements.” It is only right that the copyright owner naturally enjoys the copyright of the related output works.
When a training set containing third-party works is used, the model’s generation results represent social commonalities. This commonality is not the “thinking result” of the model creator, but the crystallization of the joint efforts within the training set, or even of all humanity. No single person should or has the right to monopolize the copyright represented by such a social commonality.
3. Copyright of Generated Works
Unless it is a work generated from a model trained entirely on one’s own works, no one should enjoy the copyright of a directly AI-generated work.
Direct AI-generated works refer to various images purely generated by an AI model without any secondary creation by the user.
The author supports the view that AI is merely a tool, but the person using AI is merely a user, not the creator of the generation result. All “works” generated by AI, at least currently, are calculation results based on mathematics and statistics. No matter how much “intellect” and “effort” a user spends before generating a result, it is merely “constantly trying to plug different parameters into a formula to get a better result.” There are actually very few human intervention factors in either the generation process or the final outcome.
“Works” directly generated by AI lack the elements of copyright and thus should not be protected by Copyright Law.
However, once secondary creation is performed based on an AI work—including repainting parts of the image, fixing structural errors, adding more elements, etc.—when the proportion of the artificially added parts surpasses the AI work itself, the user enjoys the copyright of the new work.
At this point, the AI work has merely become part of the raw material for the new work (like a reference image used in normal painting). The human “intellectual investment” has exceeded the “mechanical generation” part, thus meeting the criteria to acquire “copyright.”
VI. Conclusion
In this case, the defendant directly used the plaintiff’s image, and the author has no objections regarding this point based on current evidence.
However, the author believes that based on the technical principles discussed in this article, the plaintiff equally lacks the copyright to the image in question, and the defendant does not constitute an infringement.
Regardless of whether this case represents the “first human case” as some netizens believe, regarding the new intellectual property issues brought by AI, we should all recognize one thing: the legal protection methods and cognitive understanding related to intellectual property need to align with technical principles much faster.
Faced with IP issues of new technologies, we cannot simply follow past experience. Instead, we must start from the technical principles, conduct an in-depth analysis of the technology’s essence, and combine it with the core protective principles of intellectual property to determine whether the technology constitutes intellectual property and whether related behaviors constitute infringement.
Otherwise, it is too easy to fall into the traps of “empiricism” and “subjectivism.”
