我训练出了比谷歌、阿里更好的法律Embedding模型?
分享微调法律专用Embedding模型的完整过程:基于谷歌EmbeddingGemma-300M,使用法条-口语化提问数据集训练,在法条检索场景下超越谷歌和阿里同类模型,并已开源发布。
前段时间制作了一个查法条的软件
一开始想着自用,但后面觉得做都做了,所以也分享给大家
【自制】本地AI法条库,秒出搜索结果,支持AI直接整理结论、法条间便捷跳转、快捷引用,还有更多!
后面在用的过程中,感觉法条在召回的时候还是不够好,所以看了一眼手上的显卡
“为什么不微调一个我自己的模型呢?”
*本文仅为笔者个人观点,不视为任何法律建议或法律意见。
** 注意:这是Embedding模型,不是LLM模型,不能用于对话。
一、先看效果
对比模型
原版向量(Embedding)模型:谷歌的EmbeddingGemma-300M
国内优秀的向量模型:阿里的Qwen3-embedding-0.6b
以上两个都是非常优秀的轻量化向量模型,在世界开源向量模型排行榜上均名列前茅,且适合绝大部分设备运行。
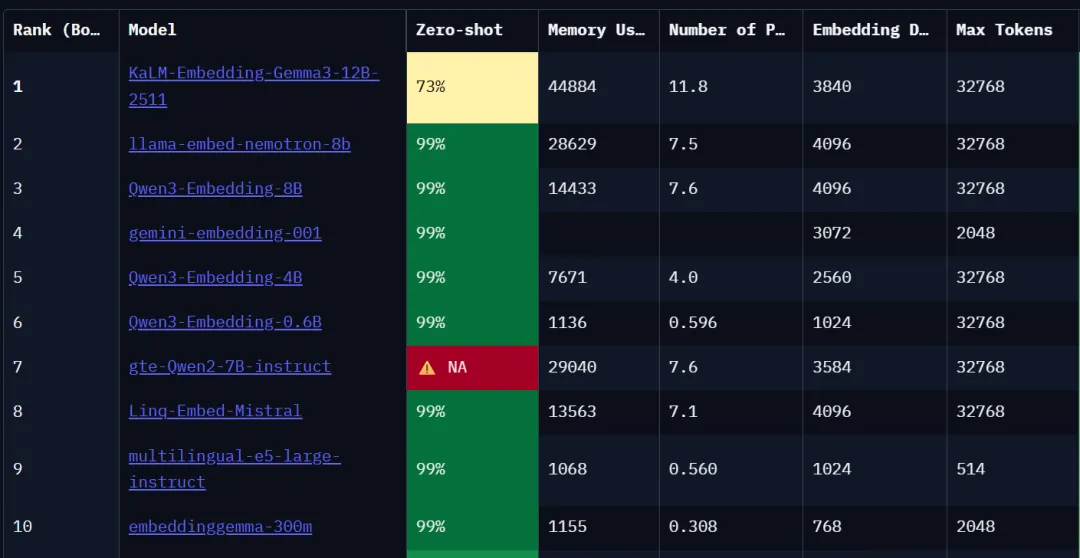
这也是我一开始选择EmbeddingGemma-300M作为法条库原版模型的原因。
对比结果
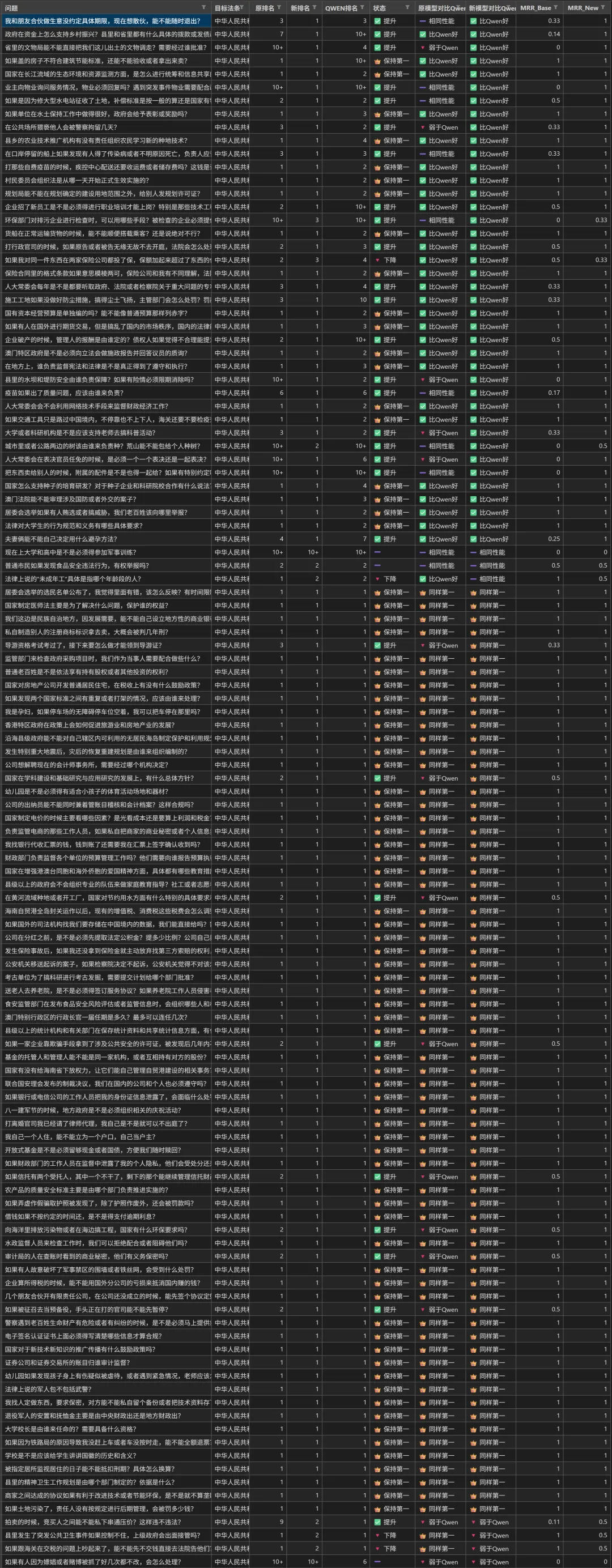
对比流程是在法条库中随机抽100多条法条,让Deepseek生成基于该法条的口语化提问内容(类似普通用户提问),然后分别对比三个模型在全部召回结果中,目标法条的具体排名。
经过微调后,结果如下图(长图预警),可见超过1/3的召回结果超越了阿里Qwen3-embedding-0.6b模型;对比原版谷歌EmbeddingGemma-300M,则有超过1/4的的召回结果排名上升:
二、开放体验
完全开放
该训练后的模型已经上传至ollama、魔搭、HuggingFace(拥抱脸)平台
ollama用户可通过以下指令拉取:
ollama pull demonbyron/embeddinggemma-300m-lawvault注:该模型为bf16量化版
魔搭模型页:
https://modelscope.cn/models/ByronLeeee/EmbeddingGemma-300M-LawVault
HuggingFace模型页:
https://huggingface.co/ByronLeeee/EmbeddingGemma-300M-LawVault
使用方法
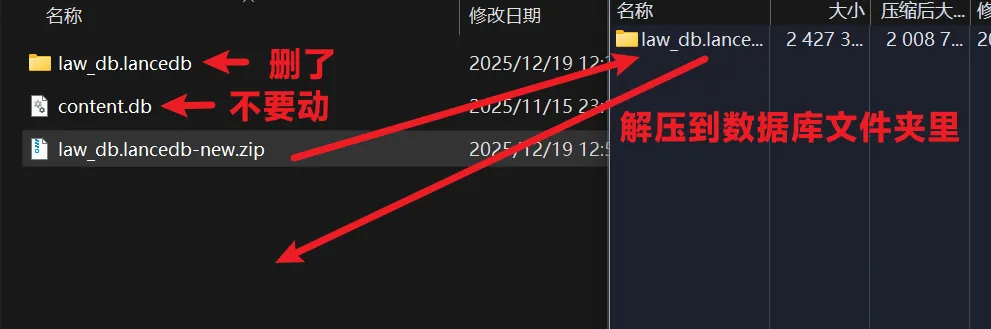
如要搭配LawVault使用,必须更新法条库文件,否则会出现无法返回正确法条的问题。
请在以下链接下载新的向量法条库文件压缩包
https://pan.xunlei.com/s/VOgpB1Qqjfe8uxRokBXzyy-BA1#
再删除原本的向量法条库文件夹(law_db.lancedb)后,把新的法条文件夹解压进去(不需要删content.db文件)
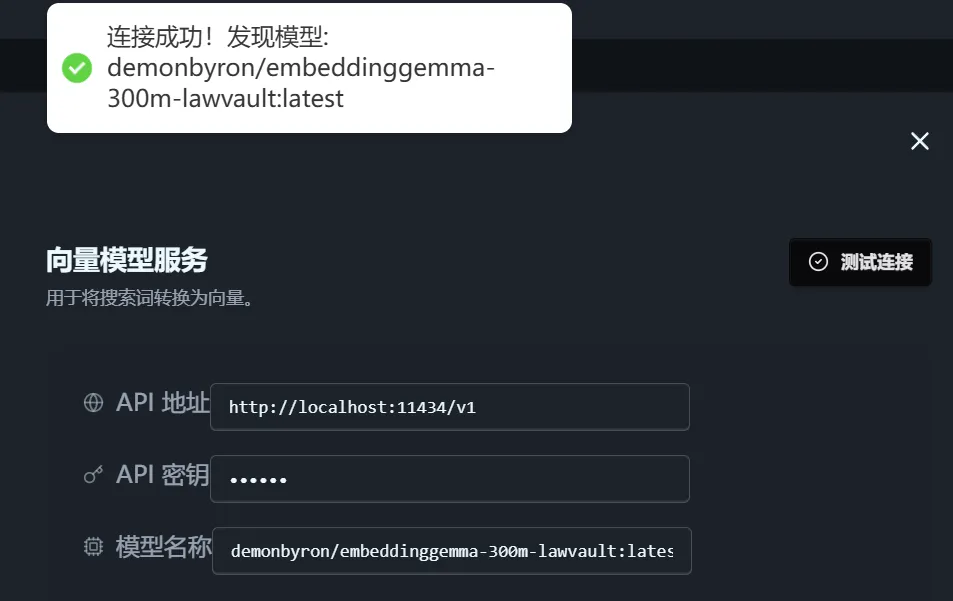
在设置中修改模型名称为
demonbyron/embeddinggemma-300m-lawvault:latest
后面正常提问就可以:
其他新增功能
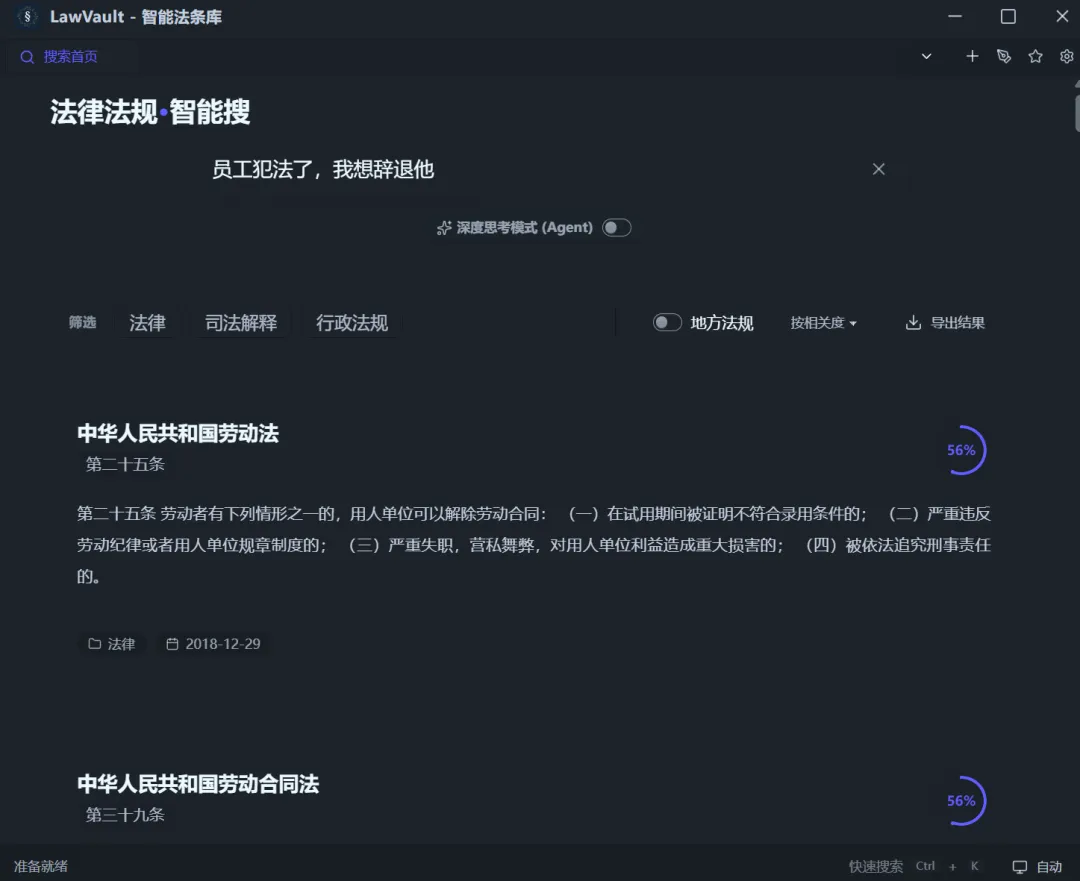
对比之前的版本,目前又新增了几个功能,欢迎体验:
【法条搜索智能体】
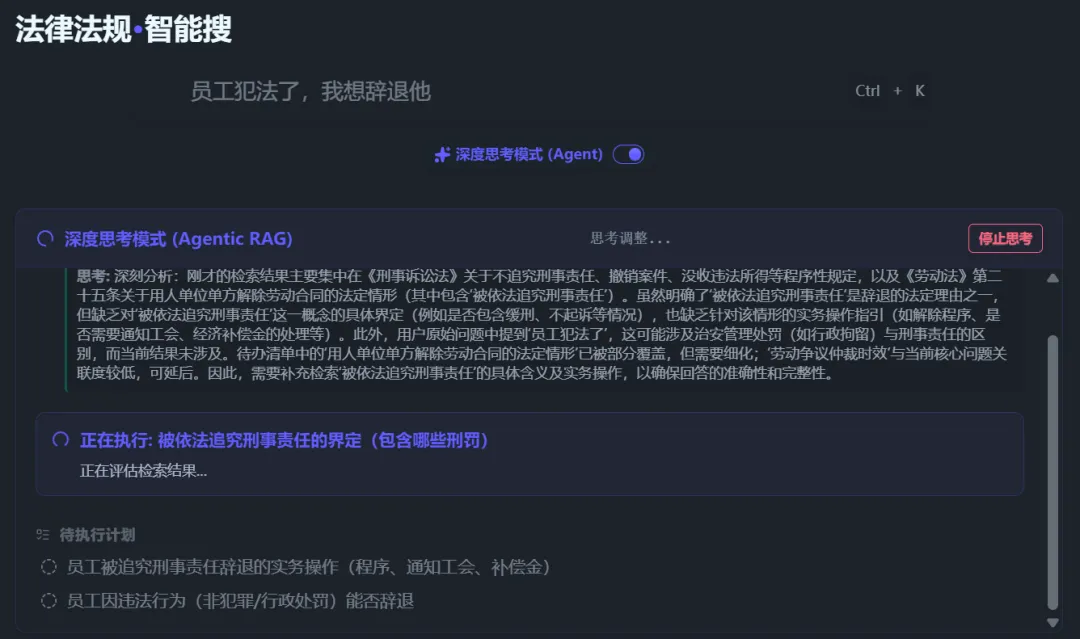
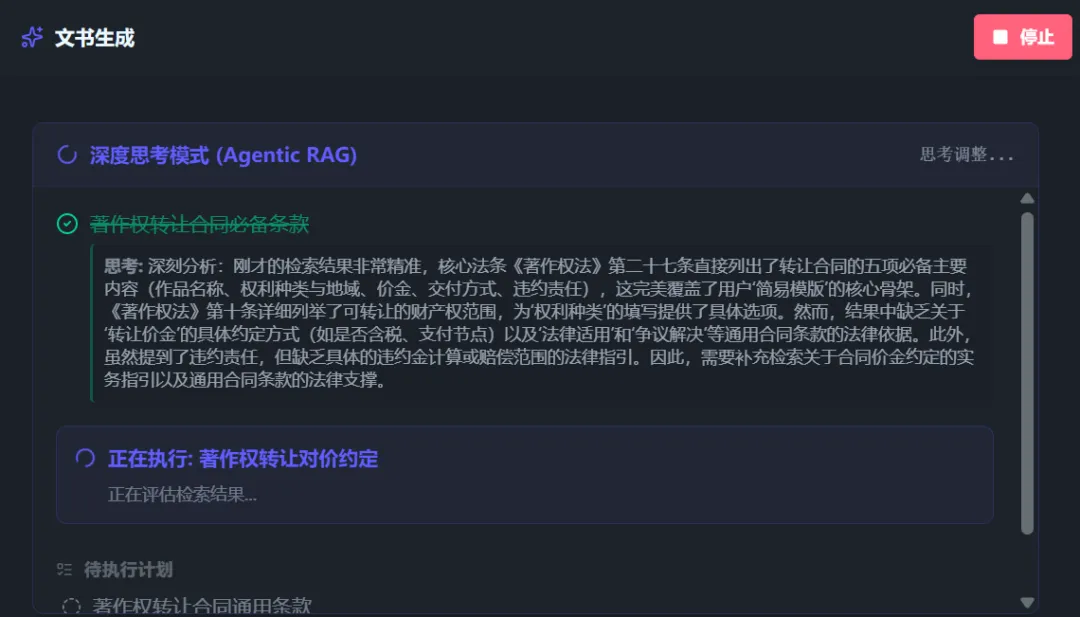
开启【深度思考模式】以及启用【AI问答】后,AI将会先对搜索问题进行拆解,列出多个搜索方向并自动进行搜索。
智能体会自动判断搜索结果是否足够回答问题,不够则继续搜索后续问题或新增搜索关键词。
当AI判断搜索完成(或达到最大搜索轮次)后,AI将会对全部搜索出来的法条进行整合,并基于问题生成搜索报告:

【写作助手】
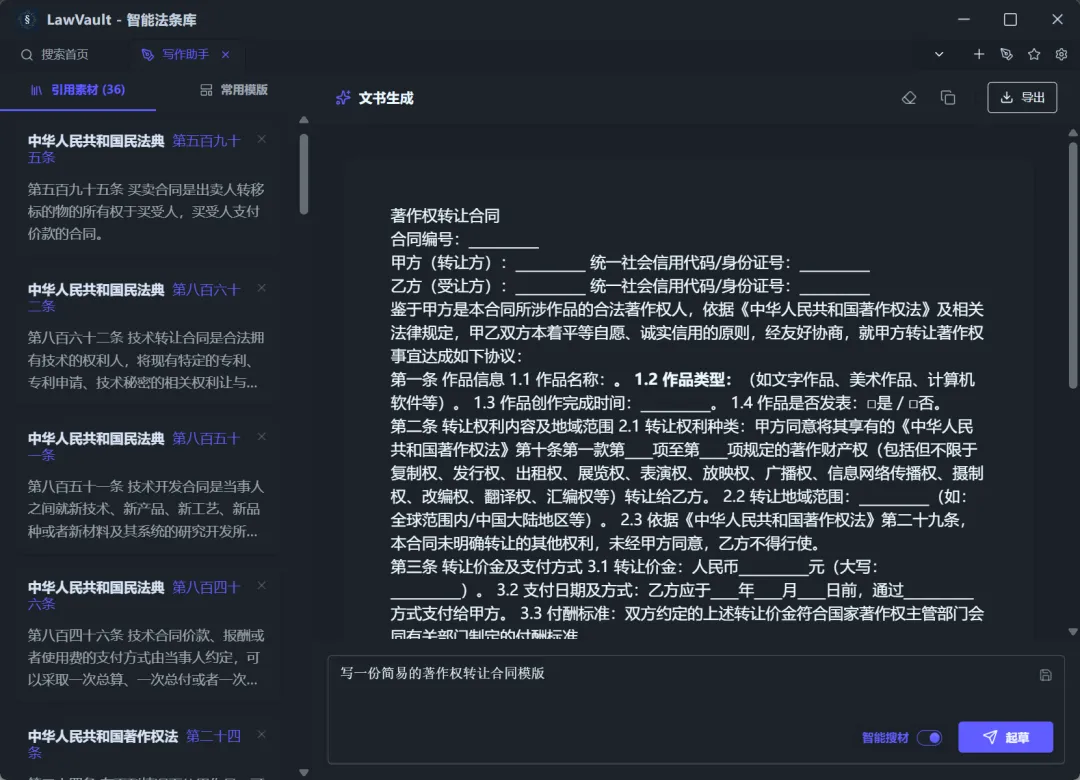
现在可以把搜索出来或在全文中选择的法条直接加入素材库,并通过写作助手功能让AI撰写所需的文本内容。
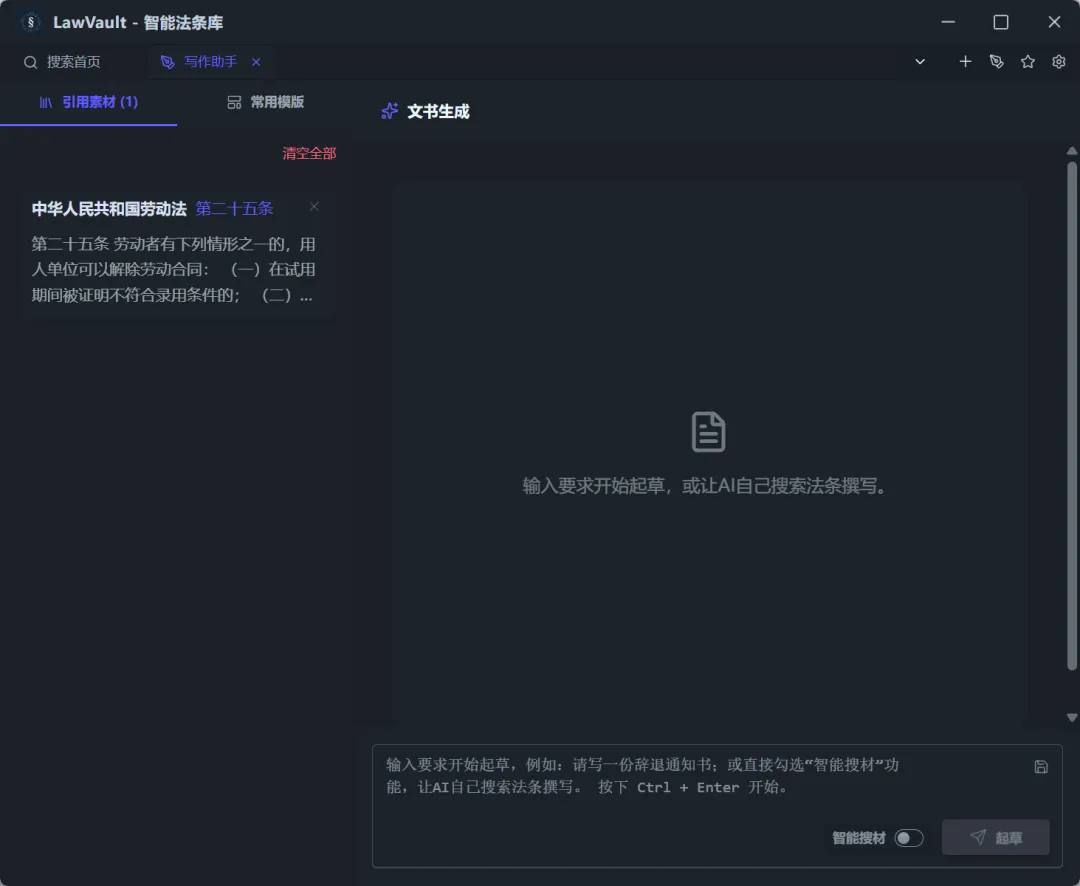
当然,也可以通过“智能搜材”功能,让AI自己搜索所需的法条进行撰写:
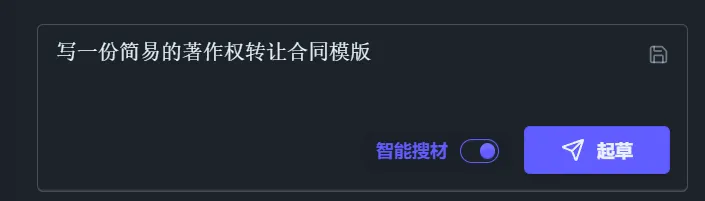
支持不同格式的导出方式,例如直接按格式复制到Word中使用:

三、原理和微调过程
以下是枯燥的原理和技术时间,如果兴趣不大,可以分享、点赞本文后叉掉,谢谢大家。
Embedding原理说明
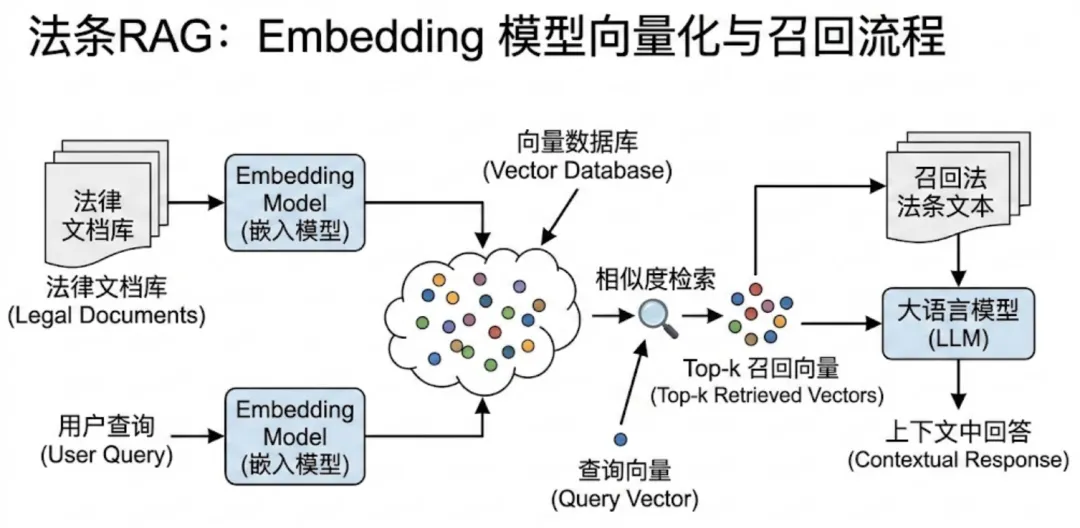
法条RAG的流程如上图。
为什么很多法条库容易找不到正确的法条?
因为向量搜索做的是【文本相似性】搜索
意味着只有搜索内容和法条文本的“法言法语”相似度较高,才能成功返回正确的对应法条。
所以容易有一个悖论:
只有“我”知道法条内容,“我”才能搜索出法条;
但“我”既然知道了法条内容,“我”为什么还要搜索?
微调过程
因此,我决定尝试微调向量模型。
首先,把已经拆分好的2万多条法律条文(纯法律,不含司法解释和地方法律法规),利用Deepseek V3.2模型生成基于该法条内容的口语化提问。
每条法条采用3种不同口吻进行提问,最终生成65783条提问。


然后,因为EmbeddingGemma(或者说向量模型)建议用三元组方式微调(文本,正向示例,反向示例),用LLM方式生成反向示例可能不够稳定,故最终采用通过获取
训练问题在原模型的向量库中,返回的向量结果里除目标法条外的最接近法条
作为反向示例,最终构成完整的训练数据集。
接下来就是常规训练,参数如下:
批量大小: 24 (有效批量大小 = 144,梯度累积)
Training Loss | ||
0.0022 | 3.5148 | |
457 | 0.2123 | |
914 | 0.0749 | |
1371 | 0.0369 |
利用RTX 5070Ti 16G训练,3轮下来大概需要2个半小时,总的来说速度还可以接受。
四、最后
其实标题有一点点“标题党”。
毕竟微调后的模型,只在【口语化法律问题和具体法条的关联性】这场景下有一定优势。
但我想说明的是,其实模型微调非常容易上手。
各家大厂提供的模型通常只是“最大公约数”,而微调一个适合自己使用的模型,可以进一步提高模型的利用率。
相信未来必然会是本地个性化小模型和在线大模型结合来使用,而有一个自己的模型,的确会很爽。
