随着接入了DeepSeek满血版,且在包括微信、搜狗输入法等多个入口大力推广,腾讯元宝迎来了又一个新春天
然而,“AI红是非多”
随着网友们深入挖掘和广泛讨论《用户协议》,一些在普通用户眼中较为“刺眼”或引发争议的内容被广为传播,让腾讯元宝面临较大的舆论压力
于是乎,一轮又一轮紧急修改《用户协议》的工作随之展开
从2025年2月27日到今天(2025年3月4日),短短不到一周时间,《用户协议》已更新了3版,不得不佩服法务团队效率之高
元宝的《用户协议》究竟改了什么?
为什么要进行这些修改?
接下来,我们将一起深入分析,探讨用户协议的变化及其背后的原因
*本文仅为笔者个人观点,不视为任何法律建议或法律意见。
一、元宝《用户协议》的演变历程
元宝的用户协议并没有提供历史版本浏览功能,但恰好,笔者也是喜欢留意《用户协议》的人,并恰好保留了2025年2月27日版本的5.4条截图
因此,就从2025年2月27日至3月4日,看看《用户协议》经历的三次更新内容是什么:
2月27日版

这版本的内容可被解读为
不管是用户提示词(Prompt),还是其他一切用于生成结果的提示性内容(包括但不限于用户上传的附件文档、图片等),以及AI生成的结果,都会不可撤销地授权腾讯拥有永久免费使用权,可用于全部能使用得上的环境
甚至这是可转让、可分许可、无地域限制的授权,意味着腾讯有权将这些资料无限制地转发给任何第三方
简单而言,等于这些内容的相关知识产权,都会无条件地交给腾讯使用
3月1日版

3月1日调整的版本中,腾讯删除了(隐藏了)明确性的“或其他一切用于协助腾讯元宝产生人工智能生成内容的提示性内容”,去除了“不可撤销的、可转让的”等等“吓人”的描述,把使用范围减少描述至“模型优化、学术研究、市场营销、用户调研”,同时还增加了“主动联系退出”机制(opt-out)
不过,这个版本的《用户协议》实际上依然要求用户将使用过程中的全部提示词、上传的内容和生成结果,授予腾讯在全球范围内的免费使用权
使用范围也依旧不够明确,仅用“例如”进行模糊表述,缺乏具体限制
退出机制也非常不方便,需要联系客服处理(但众所周知客服不好找)
3月4日版

在再次引发舆论关注后,3月4日,元宝再次更新了《用户协议》
这个版本将绝大部分内容都进一步模糊,在使用情况中只保留了用于“模型优化”
但是,这一版本引入了“体验优化计划”的概念,只有用户主动开启该计划,用户的数据才会被获取使用(即opt-in)
因笔者核查,这个“体验优化计划”是默认不勾选的,算是明确回应了用户的顾虑了

二、为什么要改?
不难猜测,元宝作为近期腾讯投入了大量精力和广告位推广的产品,属于“可胜不可败”的战略级项目
凭借其整合DeepSeek满血版,并在微信等多个高流量入口的大力推广,元宝迅速赢得了市场,尤其大量平时不用AI的人群的高度关注
当然,市场数据也给出了积极反馈:元宝成功超越DeepSeek官方APP,登顶AppStore免费榜,成为AI应用领域的一大明星产品。
然而,突如其来的《用户协议》争议却打了腾讯一个措手不及
虽然争议的起因初期仅限于法律圈和开发者圈的讨论,但随着议论的进一步发酵和扩散,尤其当各个新闻网站开始关注这个事件,考虑到另一家火热的AI“友商”也掌握了大量流量入口,其影响范围存在扩展到普通用户层级的可能
如果《用户协议》争议进一步加剧,可能会带来多重负面影响,最明显是,前期投入的大量资源和广告推广成果可能“打水漂”,用户信任度下降可能导致用户流失,甚至影响后续功能的推广和市场竞争力
其次,持续的舆论压力和用户不满可能会吸引监管层的密切关注。近年来,用户隐私问题一直是国家关注的重点问题之一,目前AI同样也是监管重点区域,元宝的相关行为一旦被认为违反相关法律法规,腾讯不仅面临罚款和高额合规成本,还可能损害腾讯整体的公信力
也正因如此,不难理解为何腾讯法务部门的反应速度如此之快
三、其他家是怎么做的?
不过与普遍认为的腾讯”霸权作恶”不同
元宝这次可能只是在遵守”行业惯例”,毕竟其他家也是这样做的
笔者在此前的文章中就已经分析过(详见:这篇),这次不妨再看看这次元宝事件后,是否会有所不同
国内
DeepSeek
DeepSeek作为目前的明星产品,也是许多人的首选AI服务,无论是《用户协议》还是《隐私协议》,都有对数据使用的说明:


DeepSeek采取的是opt-out方式撤销同意
豆包
目前与元宝、DeepSeek呈三足鼎立之势的,莫过于豆包,而豆包的《用户协议》《隐私协议》与元宝2月27日版类似,同样是用户无条件授予豆包(字节系)全球永久可转让的使用权(甚至连条款用语都差不多)


同样,豆包采取的也是opt-out方式撤销同意
海外
Claude
作为海外模型三巨头之一的Claude,在其《隐私协议》中明确,在一般情况下,不会使用用户的输入输出来训练其模型

Grok(xAI)
Grok在马斯克的豪砸下,目前在跑分上成为了AI闭源模型的领头羊,其《用户协议》与《隐私协议》,与元宝的原协议基本一致,都明确表示会利用用户的个人信息(输入输出)训练模型和新产品,要求用户授予全球免费使用权限

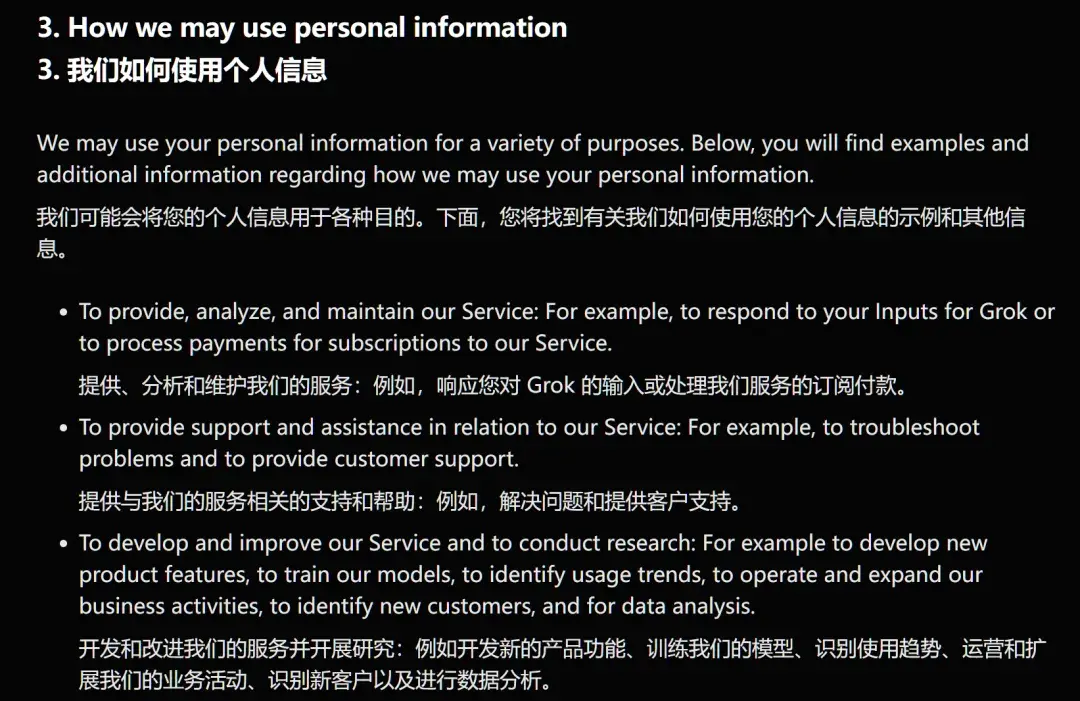
ChatGPT
作为老牌AI服务,CloseAI OpenAI同样声明会利用用户的输入来训练模型

Gemini
三巨头通常有四家,谷歌家的Gemini则在《隐私协议》中声明,会利用用户的输入输出来训练谷歌全家桶

四、总结
从上面的各家《用户协议》《隐私协议》可见,元宝的数据使用方式实际上完全符合全球绝大部分AI服务商的行业标准和规范,只是因为它是腾讯产品,而且最近实在流量太多,任何细微的条款争议都可能被放大,引发更多关注
在AI领域,数据无疑是最核心的资产。公开网络上的数据资源对于已训练的参数模型而言,已接近“枯竭”状态。因此,谁能更高效地挖掘和利用用户手中的数据,谁的下一代AI模型就可能获得更显著的技术优势和市场领先地位,这也是各家模型商开放免费模型给大家用的原因
所有命运馈赠的礼物,早已在暗中标好了价格
腾讯元宝这次主动修改《用户协议》,甚至直接改成了opt-in模式,已经属于
“非常负责任”,甚至显得过于“尽责”了
最近笔者身边用元宝的朋友越来越多,与此同时,同样获得关注的,还有腾讯旗下,接入了元宝和腾讯生态的ima.copilot(简称ima)。ima是一款以知识库为核心的智能工作台产品,可以让用户上传自己的文档构建属于自己的知识库,还可以将知识库分享给其他人,考虑到许多人在初次接触RAG时,都会对AI的输出感到非常兴奋,在近期ima凭借元宝的东风,也吸引了拥有大量文件数据的企业用户或专业人士的青睐
当然,ima的《用户协议》同样遵守了”行业惯例”,腾讯同样可以使用相关生成内容

虽然《知识库相关声明》中声明了,不会擅自利用知识库的数据训练模型

但RAG的回答方式基本会引用知识库的原文,即“AI生成的内容”中,同样可能会存在知识库的内容,在知识库的构建上,同样应该保持谨慎
不过实际上,笔者已经注意到,一些同行甚至直接将顾问公司的内部文档上传至ima,用于生成RAG来生成给公司的文件
只能说,在AI时代,许多人愿意——甚至更倾向于——用自己的隐私,甚至他人的隐私,来换取便捷、高效的服务

北京市隆安(广州)律师事务所律师、隆安湾区人工智能法律研究中心高级顾问。具有近十年互联网法律实务经验,曾先后为创业板上市互联网企业、全国互联网综合实力 50 强企业、互联网快时尚零售独角兽等互联网企业提供法律服务,擅长办理互联网类企业诉讼与合规业务,擅于通过计算机技术手段深度挖掘证据。
您可以通过以下方式联系我: 电子邮箱:[email protected] 微信号:legal-lby